
A utilização do índice B-TREE com uma coluna ou com um grupo de colunas é muito comum nas aplicações, estas colunas são referenciadas na cláusula WHERE das instruções SQL e possibilitam uma rápida recuperação dos dados que o usuário deseja, mas existem outras formas de utilizar os índices que são pouco…
O que você precisa saber sobre o uso de índices?

Existem muitos artigos na internet afirmando que a partir de um certo percentual de registros acessados em uma tabela o Otimizador do Oracle prefere utilizar uma operação TABLE ACCESS FULL, este percentual na verdade não existe, para definir o tipo de operação que vai utilizar, o Otimizador se baseia em uma série de informações que combinadas vão determinar o tipo de operação mais eficiente, neste artigo vamos abordar um destes fatores que tem um peso muito grande na tomada de decisão pelo Otimizador. Vamos entender a importância da estatística CLUSTERING FACTOR e ver na prática como ela determina que a leitura de 1% dos registros de uma tabela pode ser mais eficiente tanto para uma operação INDEX RANGE SCAN como para uma operação de TABLE ACCESS FULL.
Para realizar esta simulação vamos:
1) Criar duas tabelas para realizar as simulações
2) Executar uma consulta na primeira tabela contando o numero de registros existentes para um determinado valor da coluna RESULT
3) Apresentar os cálculos que o Otimizador realizou para escolher o acesso a tabela utilizando a operação TABLE ACCESS FULL
4) Executar uma consulta na segunda tabela contando o numero de registros existentes para um determinado valor da coluna RESULT
5) Apresentar os cálculos que o Otimizador realizou para escolher o acesso a tabela utilizando a operação INDEX RANGE SCAN
1) Criar as tabelas para as simulações
Vamos criar uma tabela com 10.000.000 de registros, sendo que a coluna RESULT possui somente 100 valores distintos e uma segunda tabela clone da primeira classificando os registros pela coluna RESULT.
Ajudo DBAs e analistas de sistema a se destacarem em suas empresas
e obter um crescimento mais acelerado em suas carreiras, quer saber mais click no link abaixo:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | SQL > SELECT * FROM V$VERSION where rownum < 2; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production Decorrido: 00:00:00.04 SQL > SQL > ALTER SESSION SET WORKAREA_SIZE_POLICY=MANUAL; Sessão alterada. Decorrido: 00:00:00.01 SQL > SQL > ALTER SESSION SET SORT_AREA_SIZE=2000000000; Sessão alterada. Decorrido: 00:00:00.01 SQL > SQL > SQL > create table dbtw101 (id , result, text ) 2 as 3 select rownum, mod(rownum, 100), 'DBTimeWizard - Performance and Tuning' 4 from dual connect by level <= 10000000; Tabela criada. Decorrido: 00:00:12.84 SQL > SQL > create index dbtw01_idx on dbtw101(result); Índice criado. Decorrido: 00:00:14.18 SQL > SQL > exec dbms_stats.gather_table_stats(ownname=> USER, tabname=> 'DBTW101', method_opt=>'for all columns size auto',cascade=>true,force=>true,degree=>16); Procedimento PL/SQL concluído com sucesso. Decorrido: 00:00:26.80 SQL > SQL > SQL > SQL > create table dbtw102 (id , result, text ) 2 as 3 select * 4 from dbtw101 5 order by result; Tabela criada. Decorrido: 00:00:16.48 SQL > SQL > create index dbtw02_idx on dbtw102(result); Índice criado. Decorrido: 00:00:10.53 SQL > SQL > exec dbms_stats.gather_table_stats(ownname=> USER, tabname=> 'DBTW102', method_opt=>'for all columns size auto',cascade=>true,force=>true,degree=>16); Procedimento PL/SQL concluído com sucesso. Decorrido: 00:00:13.52 SQL > |
2) Executar a consulta na primeira tabela
Agora vamos executar uma consulta na primeira tabela, acessando 1% do numero de linhas dela e verificar que o Otimizador vai escolher acessar a tabela utilizando uma operação TABLE ACCESS FULL.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 | SQL > ALTER SESSION SET statistics_level = ALL; Sessão alterada. Decorrido: 00:00:00.01 SQL > SQL > SQL > SELECT /* DBTW001 */ count(ID) 2 FROM dbtw101 3 WHERE result = 67; COUNT(ID) ---------- 100000 Decorrido: 00:00:16.88 SQL > SQL > -- Recupera o SQL_ID e o CHILD_NUMBER da consulta executada SQL > column sql_id new_value m_sql_id SQL > column child_number new_value m_child_no SQL > SQL > SELECT sql_id, child_number 2 FROM v$sql 3 WHERE sql_text LIKE '%DBTW001%' 4 AND sql_text NOT LIKE '%v$sql%'; SQL_ID CHILD_NUMBER ------------- ------------ d30cb6crgfyx1 0 Decorrido: 00:00:00.21 SQL > SQL > -- Gera o relatório do plano de execução da consulta SQL > SELECT * FROM TABLE (dbms_xplan.display_cursor ('&m_sql_id',&m_child_no,'typical iostats last')); antigo 1: SELECT * FROM TABLE (dbms_xplan.display_cursor ('&m_sql_id',&m_child_no,'typical iostats last')) novo 1: SELECT * FROM TABLE (dbms_xplan.display_cursor ('d30cb6crgfyx1', 0,'typical iostats last')) PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SQL_ID d30cb6crgfyx1, child number 0 ------------------------------------- SELECT /* DBTW001 */ count(ID) FROM dbtw101 WHERE result = :"SYS_B_0" Plan hash value: 3256843722 --------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers | Reads | --------------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | | 2466 (100)| | 1 |00:00:16.84 | 71843 | 71839 | | 1 | SORT AGGREGATE | | 1 | 1 | 9 | | | 1 |00:00:16.84 | 71843 | 71839 | |* 2 | TABLE ACCESS FULL| DBTW101 | 1 | 100K| 878K| 2466 (9)| 00:00:01 | 100K|00:00:16.84 | 71843 | 71839 | --------------------------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - filter("RESULT"=:SYS_B_0) 19 linhas selecionadas. Decorrido: 00:00:00.71 SQL > |
3) Verificar cálculos utilizados pelo Otimizador
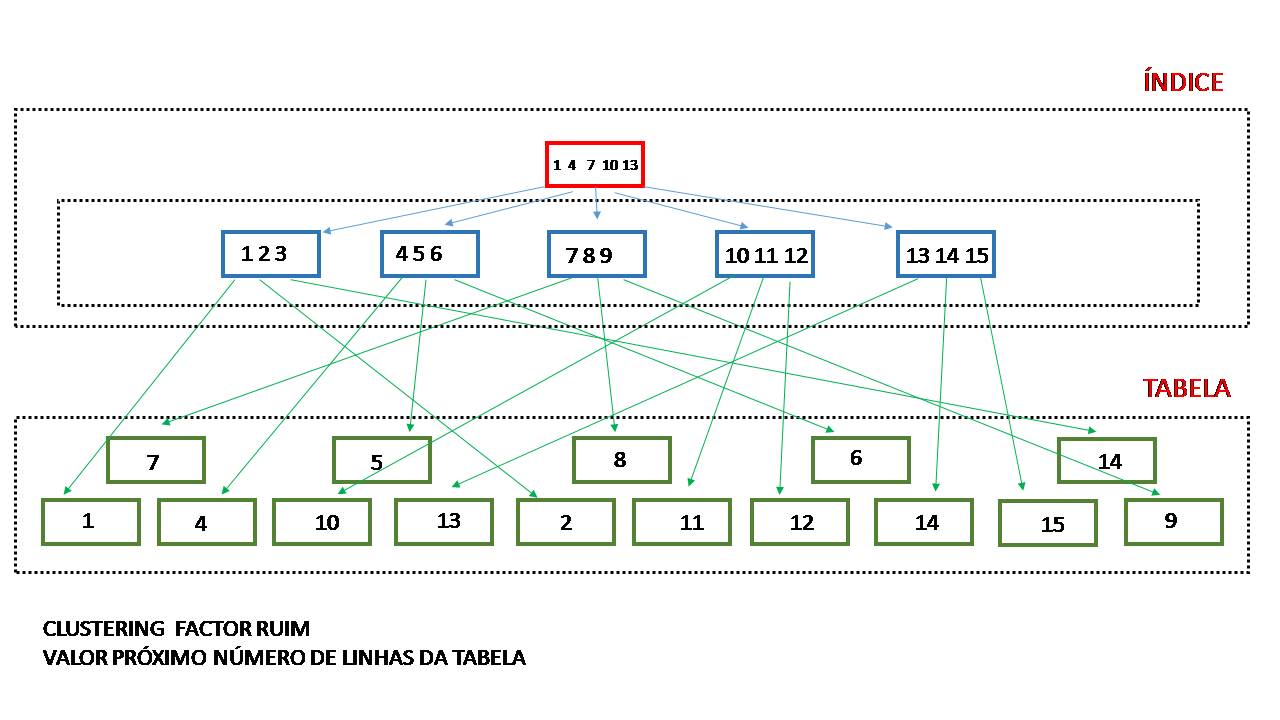
Na primeira tabela o CLUSTERING FACTOR do índice da tabela é muito ruim, o valor é bem próximo do numero total de linhas da tabela 7.287.656, isso faz com que a recuperação de linhas da tabela utilizando índice cause um volume de acesso a bloco de dados muito alto, inviabilizando a utilização do índice.
Na figura abaixo temos uma representação gráfica de um CLUSTERING FACTOR ruim, podemos observar que os blocos de índices estão totalmente desorganizados em relação aos blocos de dados, nesta situação as linhas com um determinado valor para uma coluna referenciada no índice podem estar espalhadas em vários blocos da tabela tornando o acesso com o uso do índice muito caro.
Cálculos para acessar a tabela usando índice
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | SQL > select INDEX_NAME, blevel, num_rows, distinct_keys, CLUSTERING_FACTOR, LEAF_BLOCKS from dba_indexes where table_name = 'DBTW101'; INDEX_NAME BLEVEL NUM_ROWS DISTINCT_KEYS CLUSTERING_FACTOR LEAF_BLOCKS ------------------------------ ---------- ---------- ------------- ----------------- ----------- DBTW01_IDX 2 10139378 100 7287656 19794 1 linha selecionada. Decorrido: 00:00:00.82 SQL > SQL > SELECT TABLE_NAME, COLUMN_NAME, DENSITY FROM dba_tab_col_statistics WHERE table_name = 'DBTW101' AND COLUMN_NAME='RESULT'; TABLE_NAME COLUMN_NAME DENSITY ------------------------------ ------------------------------ ------------ DBTW101 RESULT .010000000 1 linha selecionada. Decorrido: 00:00:00.18 SQL > Formula para calcular custo da operação leitura do indice: BLEVEL + (LEAF BLOCKS X DENSITY) = 2 + (19794 X 0,01) = 2 + 198 = 200 Formula para calcular custo da operação leitura da tabela pelo rowid: DENSITY * CLUSTERING_FACTOR = 0,01 * 7287656 = 72.876 CUSTO DO ACESSO A TABELA UTILIZANDO ÍNDICE = 200 + 72.876 = 73.006 |
Na primeira consulta realizada acima o Otimizador escolheu fazer uma operação TABLE ACCESS FULL pois o custo dessa operação era menor que o da operação INDEX RANGE SCAN. Nas formulas acima aplicando-se os valores estatísticos da tabela e do índice, verificamos que o custo total para acessar as linhas solicitadas pela consulta seria 73.006.
Obs: As formulas acima são aplicadas pelo Otimizador quando a consulta é realizada em apenas uma tabela e somente um filtro na cláusula WHERE, se a consulta for um join de duas ou mais tabelas e/ou houverem mais filtros na cláusula WHERE o Otimizador utilizará outras formulas.
Cálculos para acessar a tabela usando TABLE ACCESS FULL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | SQL > select NUM_ROWS, BLOCKS FROM DBA_TABLES WHERE TABLE_NAME = 'DBTW101'; NUM_ROWS BLOCKS ---------- ---------- 10000000 72226 1 linha selecionada. Decorrido: 00:00:01.18 SQL > SQL > SELECT * FROM SYS.AUX_STATS$; SNAME PNAME PVAL1 PVAL2 ------------------------------ ------------------------------ ---------- ------------------------------ SYSSTATS_INFO STATUS COMPLETED SYSSTATS_INFO DSTART 09-29-2017 21:51 SYSSTATS_INFO DSTOP 09-29-2017 21:51 SYSSTATS_INFO FLAGS 1 SYSSTATS_MAIN CPUSPEEDNW 3074,07407 SYSSTATS_MAIN IOSEEKTIM 10 SYSSTATS_MAIN IOTFRSPEED 4096 SYSSTATS_MAIN SREADTIM 5 SYSSTATS_MAIN MREADTIM 10 SYSSTATS_MAIN CPUSPEED 2618 SYSSTATS_MAIN MBRC 64 SYSSTATS_MAIN MAXTHR 262144 SYSSTATS_MAIN SLAVETHR 16384 13 linhas selecionadas. Decorrido: 00:00:00.15 SQL > Formula para calcular custo da operação leitura da tabela (TABLE ACCESS FULL): TOTAL BLOCKS / MBRC * (MREADTIM/SREADTIM) = 72226 / 64 * (10/5) = 2257 |
Quando se trata do custo da operação TABLE ACCESS FULL, ao contrário da leitura do índice usando a operação INDEX RANGE SCAN, que faz a leitura de um bloco de cada vez, nesta operação são feitas leituras de múltiplos blocos. Na formula acima temos o numero de blocos da tabela dividido pelo MBRC que corresponde a quantidade de blocos acessados em cada leitura multipla. O tempo de leitura de um bloco para Otimizador equivale ao custo 1, como o tempo de leitura de multiplos blocos (MREADTIM) é o dobro do tempo da leitura de um bloco (SREADTIM) o Otimizador considerará cada leitura de múltiplos blocos com o custo 2. Como resultado da formula acima temos um custo de 2.257 que é muito inferior ao custo da leitura utilizando índice 73.006, por isto o Otimizador escolheu fazer a leitura da tabela utilizando a operação TABLE ACCESS FULL.
4) Executar a consulta na segunda tabela
Agora vamos executar uma consulta na segunda tabela que é um clone da primeira, acessando os mesmos 1% de linhas dela e verificar que o Otimizador desta vez vai escolher acessar a tabela utilizando a operação INDEX RANGE SCAN.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 | SQL > ALTER SESSION SET statistics_level = ALL; Sessão alterada. Decorrido: 00:00:00.00 SQL > SQL > SELECT /* DBTW002 */ count(ID) 2 FROM dbtw102 3 WHERE result = 67; COUNT(ID) ---------- 100000 Decorrido: 00:00:00.82 SQL > SQL > -- Recupera o SQL_ID e o CHILD_NUMBER da consulta executada SQL > column sql_id new_value m_sql_id SQL > column child_number new_value m_child_no SQL > SQL > SELECT sql_id, child_number 2 FROM v$sql 3 WHERE sql_text LIKE '%DBTW002%' 4 AND sql_text NOT LIKE '%v$sql%'; SQL_ID CHILD_NUMBER ------------- ------------ 1fagpjtw47nfm 0 Decorrido: 00:00:00.08 SQL > SQL > -- Gera o relatório do plano de execução da consulta SQL > SELECT * FROM TABLE (dbms_xplan.display_cursor ('&m_sql_id',&m_child_no,'typical iostats last')); antigo 1: SELECT * FROM TABLE (dbms_xplan.display_cursor ('&m_sql_id',&m_child_no,'typical iostats last')) novo 1: SELECT * FROM TABLE (dbms_xplan.display_cursor ('1fagpjtw47nfm', 0,'typical iostats last')) PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SQL_ID 1fagpjtw47nfm, child number 0 ------------------------------------- SELECT /* DBTW002 */ count(ID) FROM dbtw102 WHERE result = :"SYS_B_0" Plan hash value: 2285397273 ---------------------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers | Reads | ---------------------------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | | 1115 (100)| | 1 |00:00:00.81 | 918 | 917 | | 1 | SORT AGGREGATE | | 1 | 1 | 9 | | | 1 |00:00:00.81 | 918 | 917 | | 2 | TABLE ACCESS BY INDEX ROWID| DBTW102 | 1 | 100K| 878K| 1115 (1)| 00:00:01 | 100K|00:00:00.81 | 918 | 917 | |* 3 | INDEX RANGE SCAN | DBTW02_IDX | 1 | 101K| | 201 (1)| 00:00:01 | 100K|00:00:00.21 | 199 | 198 | ---------------------------------------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("RESULT"=:SYS_B_0) 20 linhas selecionadas. Decorrido: 00:00:00.29 SQL > |
5) Verificar cálculos utilizados pelo Otimizador
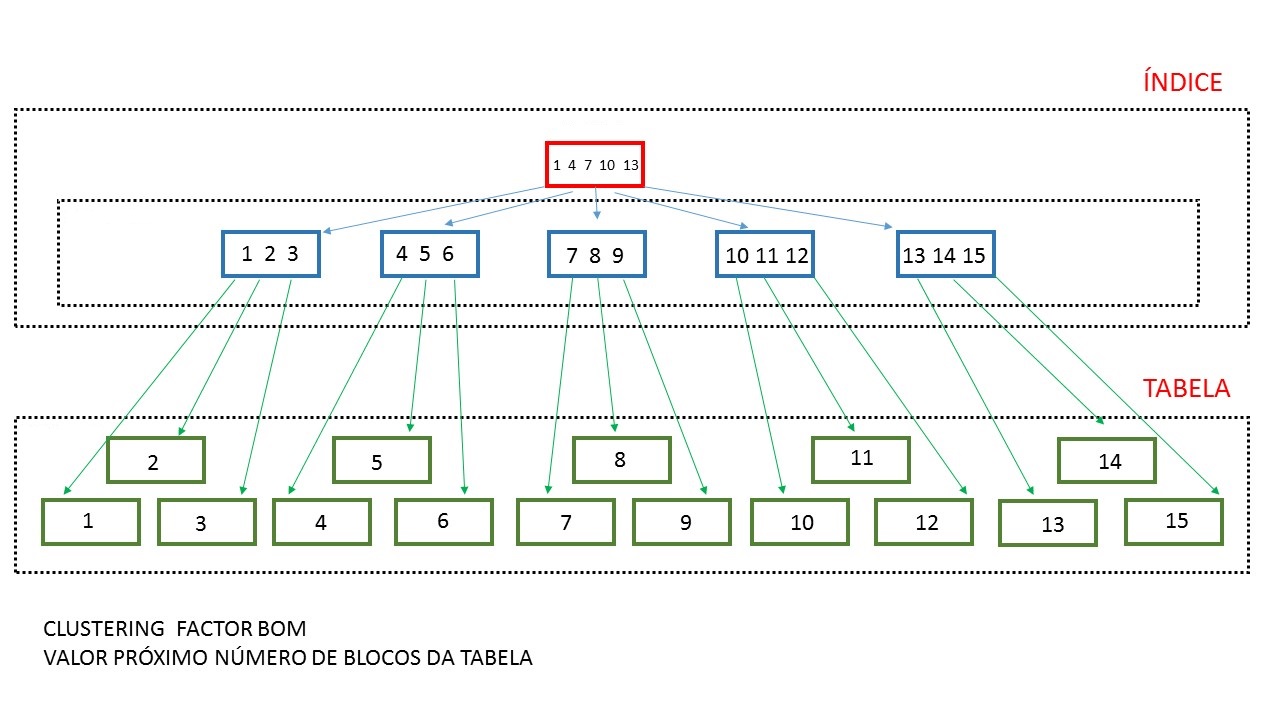
Na segunda tabela o CLUSTERING FACTOR do índice da tabela é muito bom, o valor é bem próximo do numero total de blocos da tabela 91.303, isso faz com que um acesso a tabela utilizando índice seja muito eficiente.
Na figura abaixo temos uma representação gráfica de um CLUSTERING FACTOR muito bom, podemos observar que os blocos de índices estão totalmente organizados em relação aos blocos de dados, nesta situação os registros com um determinado valor para uma coluna referenciada no índice estarão agrupados em poucos blocos da tabela tornando o acesso á tabela com o uso do índice muito eficiente.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | SQL > select INDEX_NAME, blevel, num_rows, distinct_keys, CLUSTERING_FACTOR, LEAF_BLOCKS from dba_indexes where table_name = 'DBTW102'; INDEX_NAME BLEVEL NUM_ROWS DISTINCT_KEYS CLUSTERING_FACTOR LEAF_BLOCKS ------------------------------ ---------- ---------- ------------- ----------------- ----------- DBTW02_IDX 2 10135438 100 91303 19780 1 linha selecionada. Decorrido: 00:00:00.16 SQL > SQL > SELECT TABLE_NAME, COLUMN_NAME, DENSITY FROM dba_tab_col_statistics WHERE table_name = 'DBTW102' AND COLUMN_NAME='RESULT'; TABLE_NAME COLUMN_NAME DENSITY ------------------------------ ------------------------------ ---------- DBTW102 RESULT ,01 1 linha selecionada. Decorrido: 00:00:00.27 SQL > Formula para calcular custo da operação leitura do indice: BLEVEL + (LEAF BLOCKS X DENSITY) = 2 + (19780 X 0,01) = 2 + 198 = 200 Formula para calcular custo da operação leitura da tabela pelo rowid: DENSITY * CLUSTERING_FACTOR = 0,01 * 91303 = 913 CUSTO DO ACESSO A TABELA UTILIZANDO ÍNDICE = 200 + 913 = 1.113 |
Aplicando as formulas do Otimizador e utilizando os valores estatísticos da tabela e do índice, verificamos que o custo do acesso utilizando ÍNDICE é igual 1.113, Um pouco menor do que aparece no plano de execução pois neste valor não foi computado o custo CPU.
Conclusão
Esta é uma demonstração simples para mostrar que a escolha pelo Otimizador da operação INDEX RANGE SCAN ou a TABLE ACCESS FULL nem sempre depende da porcentagem de linhas que uma consulta deve recuperar. Em vez disso, depende de fatores críticos como a distribuição de dados, o número de leaf blocks no índice, o número médio de linhas em um bloco de tabela, o número médio de entradas nos leaf blocks do índice, o clustering factor do índice e o valor do parâmetro db_file_multiblock_read_count, simplesmente não existe uma porcentagem mágica de linhas que faça o Otimizador escolher uma operação INDEX RANGE SCAN ou TABLE ACCESS FULL.
Referências:
http://docs.oracle.com/cd/E25178_01/server.1111/e16638/optimops.htm#i82433





